
Just as making marketing decisions purely on intuition is not a wise strategy, basing them only on naive data analysis is equally bad.
Kantar’s Unified Marketing Measurement and Optimization Hamilton AI marketing attribution model offers a superior combination between domain knowledge – the beliefs that you already have about how your marketing works – and new information to form a more accurate attribution and prediction of business outcomes.
Traditional MMM can produce bad models
Marketing Mix Modeling (MMM) is often used to attribute the individual effects of variables such as media spend, distribution, pricing, macroeconomic indicators, weather temperatures and even Covid-19 pandemic information to a business KPI like sales numbers.
The purpose would be to quantify the historical contribution of each variable down to a granular touchpoint-level like measuring the effectiveness of, say, Facebook advertising, and use the attribution for predicting the outcome of different scenarios. For example how many new customers alternative media plans could generate.
The problem of Overfitting
Traditionally, the method used for Marketing Mix Modeling is some form of regression analysis, often multiple linear regression. The problem with this approach is that there is at least one variable to be estimated for any given marketing and sales touchpoint, and data is usually sparse: Typical data sets are limited to a few years. With data points reported daily like media spend on for example Facebook and the number of impressions or conversions that this spend generates, we’re trying to estimate the value of thousands of observations with many possible outliers.
This leads to the problem of overfitting: The model begins to fit the noise – the variation – in the data rather than the signal: the overall trend! This means it will perform poorly at predicting the outcome of future marketing and media investments because the model is overfitted to the variation and not the real direction that these investments will take.
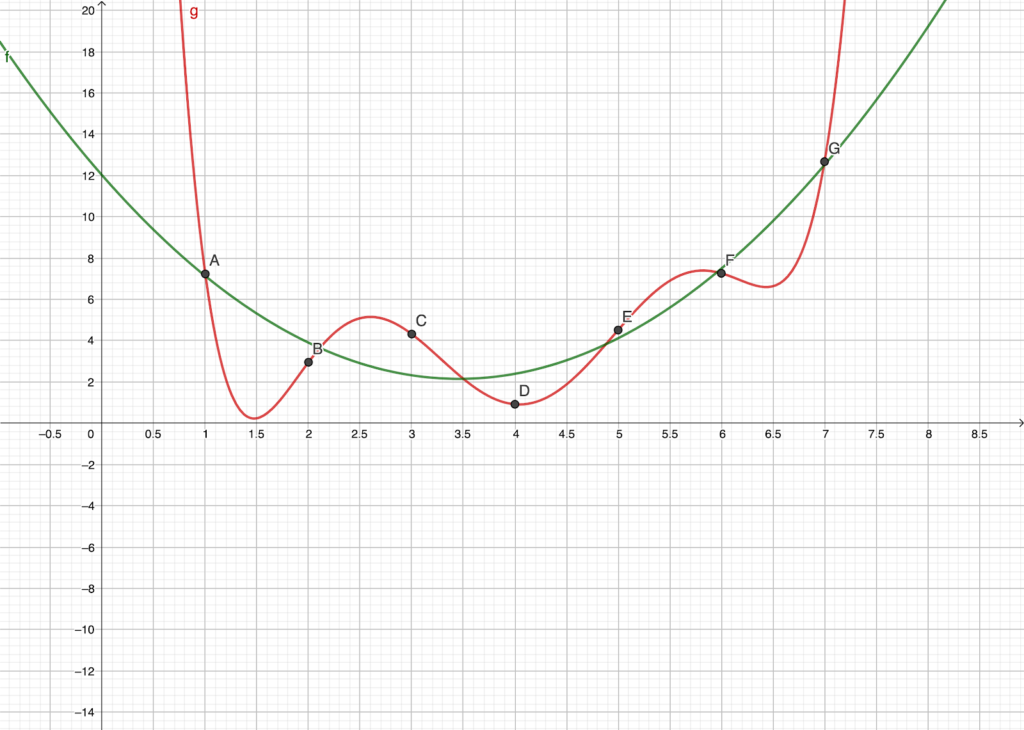
A simple example of overfitting: The red fit perfectly captures all data points, but is clearly not a very sensible model; it is too complex, overfitting the noise in the data. The green fit captures the essential behavior in the data, even if it is slightly off for each data point.
Are you wondering if applying AI to your media investments works for your business?
A realistic marketing attribution model needs domain knowledge
One of the reasons traditional regression models fail, is that the hard data isn’t equipped with any prior knowledge: the data itself doesn’t have any clue to how marketing works. Every parameter in the model is determined as if it’s in a vacuum: Each ‘knob’ in the model can be turned totally independently of all the other ones.
This is obviously not a good representation of the reality of marketing where we know that there is a strong mutual dependence between marketing activities and various marketing channels. For instance, marketers would expect media investments in TV to have comparable returns between the TV networks that the campaigns are running with. They also know that typically TV ads have high adstock half-lives (the period that it takes for half of the ad awareness to wear off) compared to other channels.
What we need is a way to incorporate such domain knowledge (in this case specific knowledge of the marketing discipline) so that it can guide the model, but how?
Bayesian methods to the rescue
Bayesian statistics is a branch of probability theory that does include domain knowledge. This is expressed through what is known as priors.
Priors encompass prior knowledge – domain knowledge – about the parameters in a model. Technically, these are probability distributions which encode the marketer’s intuition and certainty about the parameters. The prior and the information in the raw data, which is called the likelihood, is combined to produce the posterior (the models estimation of this effect). An example would be the likelihood of a TV investment to reach a certain level of awareness and how that level would then contribute to a KPI like Sales. For example the likelihood that a certain TV investment would affect another channel like Search and how much TV plus Search would then contribute to the KPI.
The combination between the two – the prior and the actual likelihood of what could happen based on the belief the prior represents – is what constitutes the final model: The best of both worlds. In the context of measuring marketing effectiveness, we call it Total Marketing Modeling because the modeling is based on a more holistic view. We try to adapt the model to how we know that marketing works from experience and prior knowledge and not the other way around.

A simple example of Bayesian modeling of a single variable. The intuition of the modeler is expressed in the prior. The information from the data is contained in the likelihood. The two combine to produce the posterior.
What’s next?
That’s not the whole story of course. Hierarchical modeling is central to the Hamilton AI approach that is used in Hamilton AI. This is how we determine which parameters, for example which specific marketing and media channel investments cause a “trickle-down” effect to other touchpoints and how they might be interdependent.
We can do this with great granularity based on insertion level data, i.e. the data we gather from a specific media placement with any given media publisher We also have Synergy models that allow us to extract insights about what indirectly drives customer behavior and conversion from one touchpoint to another. We have even developed ways to model the effects of large scale events, like the current pandemic.
Watch this space for future blog posts about these topics and more. Are you curious and want to know more – please feel free to contact us or sign up for a free trial.